
英国政府が100億円超を投じる「Safeguarded AIプログラム」とは
執筆:高槻瞭大
はじめに
AIの開発競争が激化し、AIが社会に与える影響が急激に大きくなるに伴い、AIの安全性を担保する”AI Safety”の研究が世界中で活発化しています。
そんな中、2024年の4月にイギリスの政府系研究支援機関であるARIA(Advanced Research and Invention Agency)が、“Safeguarded AI” という研究プログラムを発表しました。イギリスはGoogle DeepMindやConjectureといったAI Safety研究の最前線に立つ企業、また(最近閉鎖が決定しましたが)ニック・ボストロム率いるFuture of Humanity Instituteが存在するなど、アメリカに次ぐAI Safety研究の中心地といえます。そのイギリスが、大きな予算を投じてAI safety分野に新たなアプローチで挑もうとしています。
この研究プログラムの注目に値する点として、まずは研究総予算が5900万ポンド(日本円で約115億円)にも及ぶその規模が挙げられます。また、「数学的に安全性が保証されたAIシステムの開発を目指す」という極めて野望的な目標を掲げていることも興味深い点です。さらに、本プログラムのディレクターを務めるDavid Dalrymple(通称”davidad”)氏は、数学・計算機科学・神経科学に幅広く精通し、さらにMITの修士号を16才で取得した経歴を持ちます。その彼が5年もの月日をかけて本プロジェクトの構想を練り上げたという背景も一層の期待を抱かせます。
Safeguarded AIプログラムは、以下の三つの技術領域(TA: Technical Area)に大きく分けられています。
TA1: 理論基盤(Scaffolding)
TA2: 機械学習
TA3: 応用
さらに、TA1はTA1.1: 理論・TA1.2: バックエンド・TA1.3: HCIの三つに細分化されています。本記事執筆時点では「TA1.1」の研究提案が募集が行われています(締め切りは2024年5月28日)。
本記事では、Safeguarded AIプログラムの理論的詳細に深入りすることを避けつつも、このプログラムの目標、特に中心となるアイデアである“Gatekeeper AI”についての理解が深まるように紹介します(同プログラムのProgramme thesisを参考にしています)。
Safeguarded AIの目標
冒頭に書いたように、本研究プログラムの主な目標は、AIシステムの安全性を数学的に保証することです。背景には、AIのリスクを管理しながら、AIの社会実装を強力に進めていくねらいがあります。
近年の急速なAI研究の発展によって、現時点でも性能(AIシステムの性能は一般的にオープンデータセットを用いて評価されます)だけ見れば、社会に実装することで大きな利益を生み出す可能性のあるものは少なくなく、既に限定的な形ではあっても社会実装は行われています。しかし、そうした高性能AIがなぜうまく動くのかについては、一定のハイレベルな説明を与えることはできても、実際に内部でどのような処理が行われているか完全に人間が理解することはできずにいます。また、仮にAIシステムの内部メカニズムが完全に理解できても、実社会に自由度が高い状態で実装したときにどのようなリスクがあるのか見通すことは困難です。ナイフの構造を理解したからと言ってナイフで負傷する人がいなくならないことからわかるように、技術を理解することと、その危険性を回避することは別の問題なのです。
そこで、本研究プログラムでは、自律型AIエージェントが現実世界と取りうる相互作用やその影響を完全に理解し、AIエージェントが現実世界で安全に動作することを保証する”gatekeeper”システムの構築を目指すとしています。注意すべきなのは、gatekeeperシステムは別の場所で開発されたAIシステムの安全性を保証することを目指すのではなく、安全性が検証しやすい高性能のAIシステムを1から作ることを目指しているということです。このgatekeeperシステムが無事構築された暁には、システムの頑健性が非常に重要視される、電力・通信といった社会インフラ等にAIを安全に導入することが可能になります。
既存アプローチの問題点
ただし、これまでもAIの安全性を保証するための様々なアプローチが存在します。Program thesisでは、その主力である二つの既存アプローチを取り上げ、その問題点を説明しています。
一つ目は、データセットによる検証(”Evals”)です。これは、AIシステムに対してさまざまな入力を用意し、それらに対する出力から評価された安全性が基準値よりも高ければデプロイするというものです。これは最も単純なAIシステムの評価方法であり、さまざまな特化型AIの性能評価に用いられています。
しかし、データセットに含まれない入力に対する安全性についての保証を行うことはできず、現実世界においてAIシステムが受け取りうる入力を列挙しきれない以上、この手法では不安が残ります。

データセットによる検証(”Evals”)の概念図 出典:ARIA “Safeguarded AI: constructing guaranteed safety Programme thesis v1.1” より引用
二つ目は、レッドチーミングと呼ばれる手法です。これは、さまざまなユーザーがAIシステムを危険な出力を行うように誘導し、もし危険な出力が確認されなければデプロイするというものです。これもまた、AIの安全性の文脈でよく用いられるとても実用的な手法であり、例えばOpenAIは2023年にOpenAI Red Teaming Networkと呼ばれるレッドチーミング部隊への参加者を、さまざまな分野の専門家を対象に募りました。しかし、この手法もまた、人間を必要とするためスケーラブルではない、人間はあらゆるリスクを網羅できない、といった問題点があります。
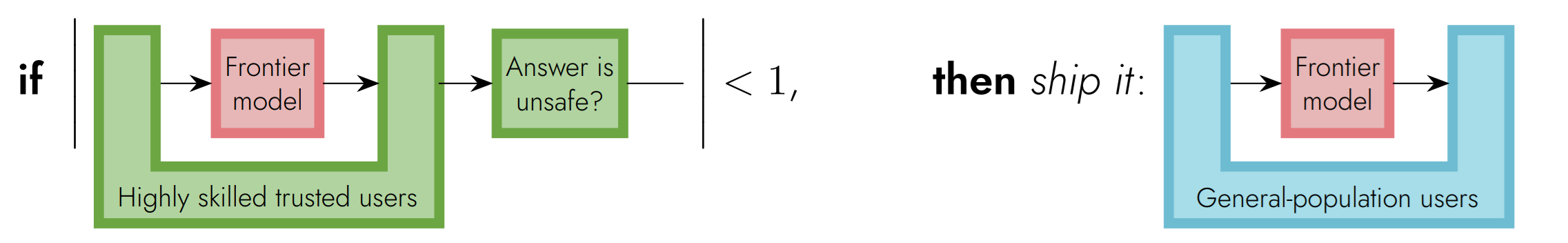
レッドチーミングの概念図 出典:ARIA “Safeguarded AI: constructing guaranteed safety Programme thesis v1.1” より引用
Gatekeeperアプローチ
こうした既存アプローチの欠点を克服するために、Safeguarded AIプログラムは、現実世界において考えられるあらゆる初期条件を考慮し、その安全性が一定確率以上である証明を獲得することによってAIシステムの安全性を保証する「Gatekeeperアプローチ」を提案しています。

Gatekeeperアプローチの概念図 出典:ARIA “Safeguarded AI: constructing guaranteed safety Programme thesis v1.1” より引用
より具体的には、以下の図に表すようなワークフローが想定されています。
安全性の数学的検証のために必要な要素として、安全性の仕様が含まれた現実世界の数学的モデルを構築する。
その構築過程を人間が監査できるようにするためのバージョンコントロールシステム(図中央の黄色い長方形)を構築する。
人間が直接数学的モデルを記述することは困難であるため、人々がリスクや安全性仕様について行う議論(collective deliberation)によって微調整したフロンティアモデルに定量的な安全仕様パッチを書かせる。
同様の方法を用いて、科学論文や科学的データに基づいて数学的モデルの改善を行う。このように構築された数学的モデルを用いて、自律型AIシステム(Autonomous AI system)が安全性仕様を満たす振る舞いを取るように強化学習で訓練する(図右上)。
訓練が終わると、AIシステムが安全性の基準を満たすという証明を探索するフェーズに移る。
この探索が成功すれば証明検査器(verified proof checker)によって証明の正当性が確認され、AIシステムの現実世界へのデプロイに移ることができる(図下)。一方で、もし証明探索に失敗すれば強化学習のフェーズに戻る必要がある。

Gatekeeperアプローチにより安全なAIを構築するワークフローの概念図 出典:ARIA “Safeguarded AI: constructing guaranteed safety Programme thesis v1.1” より引用
以上は、本プログラムの研究公募前に描かれたアプローチのラフスケッチに過ぎず、システムの細部の多くは未確定の状態です。よって、筆者にとっても不明な点が多々あり、今後このような下絵が本当に実現するのかは要注目です。
研究プログラムの進め方
上記のように、gatekeeperアプローチは、安全保証の厳密性向上やスケーラビリティの点で既存アプローチの欠点を補いうることはわかりました。しかし、数学的モデルや証明探索などを実際に形にしようとすると非常に難しそうです。Safeguarded AIプログラムではまさにこの具現化を目指していますが、実施にどのように研究を進めようとしているのでしょうか。
冒頭で述べたように、Safeguarded AIプログラムは三つの技術領域(TA)に分割されています。
TA1 “Scaffolding”(理論基盤)では、現実世界での安全性の検証を数学的に行うことが可能であると示すことを目標にしています。より具体的には、安全性仕様を形式的に定める(TA1.1)、安全性仕様の管理のためのバージョンコントロールシステムを開発する(TA1.2)、さらに人間の意見を安全性仕様に反映させるためのインターフェースを開発する(TA1.3)の三つに分けられています。
TA2 “Machine Learning”では、現実世界の安全性仕様を満たしつつ性能の高いAIシステムを訓練することを目標にしています。具体的には、人間と数学的モデルの橋渡しを行う機械学習モデルの開発(TA2.1)、証明探索のための機械学習モデルの開発(TA2.2)、安全性仕様を満たすようにAIシステムを訓練するための強化学習手法の開発(TA2.3)、多様なステークホルダーがAIシステムの安全性に関して合意を行うプロセスの確立(TA2.4)の四つの領域に区別されています。
ここまでを手法と対象によって整理すると以下のようになります。

TA1とTA2の部分領域の整理 出典:ARIA “Safeguarded AI: constructing guaranteed safety Programme thesis v1.1” より引用
TA3 “Applications”では、TA1とTA2で開発された技術を実社会に応用することを目標にしています。ここではすべてには触れませんが、エネルギーシステムや通信ネットワークといった社会インフラシステムの最適化から、感染症対策や気象予測の最適化、さらには研究開発のマネジメントまで広く射程をとっています。これらはどれもAIシステムの誤動作が深刻な結果をもたらしかねない、高い安全性と信頼性が求められるユースケースです。
これら三つの技術領域は基本的に上で紹介した順番に研究が進められると考えてよいでしょう。というのも、後の技術領域は前の技術領域を前提とするものだからです。以下の図はこの依存関係をよく表しています。一方、この図に表現されていない点として、TA1.1のすぐ後に、TA3のPhase 0として、gatekeeperシステムの利用を考えている起業家をはじめとした人々のニーズを深く理解することが計画されています。

各TAの部分領域の相互連関図(TA1で構築する数学的な言語に基づき、TA2で運用可能な機械学習モデルを実現する。こうして構築されたgatekeeperシステムの応用をTA3で扱う。) 出典:ARIA “Safeguarded AI: constructing guaranteed safety Programme thesis v1.1” より引用
おわりに
Safeguarded AIプログラムは、AIアライメント分野で議論されてきたリスクを踏まえて、AIモデルを社会の根幹システムに応用するためのロードマップを、具体的な研究計画に落とし込んだ壮大なプロジェクトと言えます。
本プログラムにおいてAIシステムの安全性の証明可能性の土台となる理論(特にTA1.1で扱われる内容)には、数理論理学や圏論といった分野が重要な位置を占めることが予定されており、これらの分野の研究者の協力が必要とされています。これらは現在主流のAI Safety研究とは毛色の異なる方法論をとっているといえますが、Safeguarded AIプログラムの規模の大きさや問題意識の説得力を考えると数年でAIアライメント研究の景色をガラリと変える可能性が大いにあるのではないでしょうか。
実際にProgram thesisでは、本プログラムの一部でも成功すれば、経済的競争力とAIシステムの安全を保証するのに必要なコミットメントの間にあるトレードオフ(下図)を大きく改善し、企業や国家といったプレイヤーが合理的な選択肢として安全性を重視するようになるのではないかと述べています。

人間を超えるAIの安全保証(Safeguard)の研究へコミットするかを判断する経済的な主体は、ゲーム理論的なジレンマ状態に直面する。現状では、開発に掛かる時間が長く、経済的競争性も低い右上の領域だと認知されているため、安全保証つきAIへの協力戦略は選ばれないが、本プログラムにより右下の領域に移行することで、協力が合理的な戦略となることが期待できる。 出典:ARIA “Safeguarded AI: constructing guaranteed safety Programme thesis v1.1” より引用
Safeguarded AIの今後の進展に注目です。
謝辞:本プログラムの背景について有益な情報をいただいた株式会社アラヤのManuel Baltieri氏に感謝いたします。
※本記事の許可のない転載を禁じます。